

Learning With LLMs: Supporting Complex Reasoning, Planning And Argumentation, Applied To Providing Educational Guidance
UCL, JSI, University of Bologna, Fortiss, OptimalAI,Tilde
Original Aims
Despite their impressive performance on a wide variety of tasks, Large Language Models (LLMs) fall short on tasks that involve complex reasoning, argumentation and planning. The aim of this macro-project is (i) to investigate how LLMs can assist humans in complex reasoning and argumentation (Task 1); (ii) to extend LLMs with a modular architecture of symbolic components to enable planning and reasoning (Task 2); and (iii) validate this architecture in providing guidance on educational pathways, which will require reasoning and planning capabilities (Task 3).
Scientific Results/Insights Summary
As GenAI becomes more reliable, competent and trustworthy, many more apps will become available that are intended to augment human knowledge activities, such as decision-making, problem-solving, writing, designing, and reasoning. The question is how best to achieve this such that humans are still engaged. This MP covers recent research into human-centred AI that has investigated how new AI tools can be designed to enhance human learning, creativity and working – where the AI works with us and not replace us. A focus is on the roles that the AI can play in helping us to reason and reflect more – through making us think differently. We propose that new models of AI-cognition are needed that can explain and predict how to truly empower people with new capabilities.
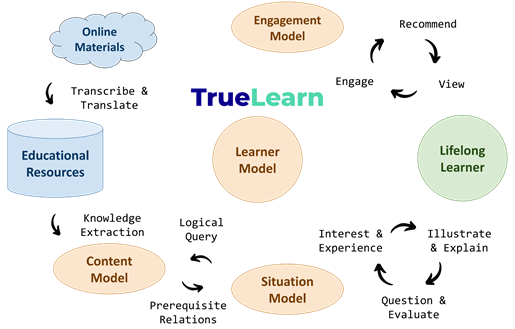
One of the most ambitious use cases of computer-assisted learning is personal recommender systems for lifelong learning which require sophisticated recommendation models accounting for a wide range of factors such as background knowledge of learners and novelty of the material while effectively maintaining knowledge states of learners for significant periods of time (Bulathwela et al., 2020). A foundational component in such systems is a model that captures and tracks learners’ knowledge states in order to assist them on their path of knowledge discovery and acquisition. One such model – TrueLearn – uses Bayesian algorithms and defines knowledge components in terms of Wikipedia topics to provide transparent estimates of learners’ knowledge states (Bulathwela et al., 2020; Qiu et al., 2023). While models such as TrueLearn could form the backbone of a lifelong learning recommendation system by tracking learners’ progress through engagement with open educational resources, many aspects and challenges associated with such a personal recommender are left unaddressed – not least the model “cold-start problem” which is relevant when onboarding a new learner (Bulathwela et al., 2021b).
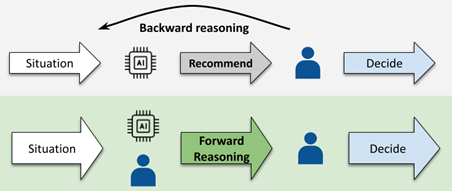
TrueReason Assistant attempts to build on transparent models such as TrueLearn while broadening the scope of the application to address issues which include:
- Learner onboarding: When a new learner begins to use the personal recommender, a new model will need to be initialised to represent the learner’s knowledge state as accurately as possible to provide relevant recommendations early on. In this case it is useful to elicit learners’ background knowledge in a more direct way than observing engagement and use an alternative recommendation strategy until TrueLearn has a robust estimate from engagement events (Bulathwela et al., 2021b).
- Learning goals: To assist the learner beyond recommending novel and engaging educational content, it is useful to base interactions on a basic situation model which firstly keeps track of learning goals but also allows the learner to monitor and steer their own progress by providing relevant information and feedback about knowledge components and their own knowledge state. This augments learners’ agency and allows them to take control of their learning trajectory instead of being passive receivers of recommendations (Reicherts et al., 2022) – see Figure 1.
- Content ontology: In contrast to traditional courses for more short-lived educational scenarios, lifelong learning supported by open educational resources has to contend with a more diverse and rapidly changing set of resources which are likely not designed to compose as do lectures in a more formal setting. However, being able to inform learners according to the structure and relations between materials could assist them on their learning path (Ilkou et al., 2021).
- Knowledge review: Appropriate question generation models (Bulathwela et al., 2023) could be used to allow learners to test their knowledge or serve as a source of information to initialise or verify the learner knowledge state estimated by TrueLearn.
- Knowledge gaps: Because the available set of educational resources are not necessarily designed to be comprehensive combined with the absence of a formal educator, learners may find that knowledge gaps persist after engaging with materials or that they need clarity on unfamiliar concepts. These gaps or explanations could be addressed by world knowledge contained in a large language model or methods for generating analogical explanations (Sourati et al., 2024) which rely on learners’ background knowledge.
Figure 2 summarises the components and interactions of TrueReason Assistant.
Innovation and Industry Cooperation Potential
The macroproject saw significant industrial involvement, particularly through collaborations with key industrial partners Fortiss and Tilde. Both organizations played an instrumental role in contributing to the project’s objectives. Fortiss provided valuable insights and technological suggestions, enhancing the project’s technical framework, while Tilde brought their expertise in language technology solutions, helping to shape and refine the project’s deliverables. The active participation of these industrial partners not only ensured the project remained aligned with market needs but also facilitated the potential of integration of cutting-edge technologies into the project’s workflow. OptimalAI played a key role in assessing the business value of the project by conducting thorough market analysis and identifying potential customers who could benefit from the solutions being developed. Their efforts were focused on understanding how the project’s outcomes could be positioned to meet specific industry needs and deliver tangible value. OptimalAI also explored possibilities for further development, including suggesting the creation of a web application to enhance accessibility and usability for end-users in showcasing the interface component. This web app concept aimed to provide a seamless interface for interacting with the project’s solutions, making it easier for businesses to integrate and leverage the technology in their operations.
Tangible Outcomes
Publications
Wu, Z., Suraworachet, W., Uzun, Y., Hao, X., Cukurova, M., Pérez-Ortiz, M., & Bulathwela, S. (2024). Leveraging Artificial Intelligence to Increase Higher Education Stakeholders’ Awareness of Sustainable Development Goals. Sustainability (Under Review).
Li, Z., Cukurova, M., & Bulathwela, S. (2024). A Novel Approach to Scalable and Automatic Topic-Controlled Question Generation in Education. In Learning Analytics & Knowledge Conference . ACM (Under Review).
Fawzi, F., Balan, S., Cukurova, M., Yilmaz, E., & Bulathwela, S. (2024). Towards Human-Like Educational Question Generation with Small Language Models. In International Conference on Artificial Intelligence in Education (pp. 295-303). Cham: Springer Nature Switzerland.
Bulathwela, S., Pérez-Ortiz, M., Holloway, C., Cukurova, M., & Shawe-Taylor, J. (2024). Artificial Intelligence Alone Will Not Democratise Education: On Educational Inequality, Techno-Solutionism and Inclusive Tools. Sustainability, 16(2), 781.
Qiu, Y., Djemili, K., Elezi, D., Shalman, A., Pérez-Ortiz, M., Yilmaz, E., Shawe-Taylor, J. & Bulathwela, S. (2024). A Toolbox for Modelling Engagement with Educational Videos, In Proceedings of the AAAI Conference on Artificial Intelligence.
Fawzi, F., Amini, S., & Bulathwela, S. (2023). Small Generative Language Models for Educational Question Generation. In Proceedings of the NeurIPS Workshop on Generative Artificial Intelligence for Education (GAIEd), New Orleans, LA, USA (Vol. 15).
Wu, Z., Bulathwela, S., & Koshiyama, A. (2023). Towards Auditing Large Language Models: Improving Text-based Stereotype Detection. In Proceedings of the NeurIPS workshop on Socially Responsible Language Modelling Research.
Bulathwela, S., Muse, H., & Yilmaz, E. (2023). Scalable Educational Question Generation with Pre-trained Language Models. In International Conference on Artificial Intelligence in Education (pp. 327-339). Cham: Springer Nature Switzerland.
Shawe-Taylor, J and Dignum, F (2024) Human-centric AI and Education, Journal of Artificial Intelligence for Sustainable Development 1 (1), 8-11, (2024) DOI: 10.69828/4d4k91. https://projecteuclid.org/journalArticle/Download?urlId=10.69828%2F4d4k91
Toolsets
Truelearn Python Library: https://truelearn.readthedocs.io/en/stable/
Datasets
PEEKC Dataset: GitHub – sahanbull/PEEKC-Dataset: To make the peek dataset available
Videos or Demos
https://www.youtube.com/watch?v=c1DEin0zgJ4
https://youtu.be/3vOdbyzH_C4?si=H-laMq3mUXw8Z5Y8
https://youtu.be/XF7K05NUGOg
Events Organized/participated in




Collaboration Outside the Consortium (in particular with AIoD etc)
During the course of the microproject, the team engaged in several discussions with Marco Hirsch (DFKI), aiming to explore potential collaboration opportunities. These conversations were focused on leveraging the AI-on-demand platform provided by the AI4Europe initiative (https://www.ai4europe.eu/). The team sought to understand how the platform could support their project goals and foster further collaboration, with the intention of integrating resources and expertise available through the portal to enhance the project’s outcomes. The main idea was to move forward and ingest educational materials from the AIoD portal.

