

Co-evolution of large-scale networked and collaborative human-AI ecosystems
Università di Pisa, University Warsaw, CNR, Università di Trento, SNS, CNR, UNIPI, Victoria University Wellington, IIT-CNR
Co-evolution of large-scale networked and collaborative human-AI ecosystems
The objective of this macro-project is
- to study the co-evolution of humans and models, especially LLMs/LGMs, in large-scale humane-AI ecosystems
- to understand and improve task allocation/role distribution
- to model emergent behavior and network effects in the interaction between humans and generative AI models
The macro-project includes 3 main topics:
1 HABA-MABA-inspired collaboration and task delegation in human-AI ecosystems.
This topic is divided in 2 subtopic:
a. LLMs and Cognition: From Representation Biases to a Theory of the Mind.
While LLM foundation models can handle language and imagery at unprecedented breadth, recent research has underlined that they may exhibit many cognitive biases humans possess. Therefore, widespread interaction with biased LLMs may reinforce harmful stereotypes that we should aim to eradicate. This risk is augmented by the fact that most present-day LLM users come from various backgrounds and are not trained to be critical consumers of LLM-produced content, in contrast to earlier human-automation interaction. Therefore, to facilitate responsible human-AI interaction that mitigates the risk of exacerbating harmful stereotypes, it is ever more critical to understand how cognitive biases emerge from the cognitive architecture of LLMs.
To such an extent, our work focused on two directions: i) defining a model to proxy LLM cognition patterns using cognitive network science [1] theory, and ii) studying the emerging patterns that characterize LLM agents’ interactions while simulating an opinion dynamic process. Both analyses focused on comparing LLM cognitive model instances and opinion dynamics behaviors with the ones known to approximate human beings.
In [2], we focused on constructing and analyzing a free association network built on top of a psychological experiment involving heterogeneous LLM models. Word associations have been extensively used in psychology to study the rich structure of human conceptual knowledge. The absence of large-scale LLM-generated word association norms comparable with human-generated norms limits the comparative analyses that can be conducted. To overcome this, we create LLM-generated word association norms modeled after the Small World of Words (SWOW) human-generated word association norms consisting of over 12,000 cue words. We prompt the language models with the same cues and participant profiles as those in the SWOW human-generated norms [3], and we conduct comparative analyses between humans and LLMs that explore differences in response variability, biases, concreteness effects, and network properties. Our exploration provides insights into how LLM-generated word associations can be used to investigate similarities and differences in how humans and LLMs process information. Human-generated responses are much richer and more varied than LLM ones. We also observe stronger gender biases and weaker concreteness effects in the LLM-generated norms compared to the human-generated norms.
In [4], conversely, we focused on implementing an opinion dynamic simulation by exploiting networked LLM-enhanced agents to replicate human-like discussions. Assuming a Deffuant-like [5] bounded opinion model, our analyses unveiled the tendency – transversal to heterogeneous LLM models – to establish convergence toward the positive end of the opinion spectrum. Such a result – explicable by the assertiveness and guardrails that are known to characterize LLM models – depicts a noteworthy difference from what is observed and often modeled when considering human-centered opinion diffusion phenomena. Moreover, an analysis of the texts generated by the LLM agents during the unfolding discussion – each aimed to convince the interlocutor to change its opinion – unveiled the presence of a relevant adoption of logical fallacies (particularly credibility, relevance, and generalization ones) and assessed their effectiveness in producing subtle shifts of agents’ opinions.
[1] Stella, M., Citraro, S., Rossetti, G., Marinazzo, D., Kenett, Y. N., & Vitevitch, M. S. (2022). Cognitive modeling with multilayer networks: Insights, advancements and future challenges. arXiv preprint arXiv:2210.00500.
[2] Abramski, K., Lavorati, C., Rossetti, G., & Stella, M. (2024). LLM-Generated Word Association Norms. In HHAI 2024: Hybrid Human AI Systems for the Social Good (pp. 3-12). IOS Press.
[3] S. De Deyne, D. J. Navarro, A. Perfors, M. Brysbaert, and G. Storms, “The “small world of words” English word association norms for over 12,000 cue words,” Behavior research methods, vol. 51, pp. 987–1006, 2019.
[4] Cau, E., Morini, V., Rossetti, G. (2024). LLM Opinion Dynamics: Polarization Trends, Models’ Agreeableness, and Logical Fallacies. Under submission.
[5] Deffuant, G., Neau, D., Amblard, F., & Weisbuch, G. (2000). Mixing beliefs among interacting agents. Advances in Complex Systems, 3(01n04), 87-98.
b. Task allocation and role distribution in humane-AI ecosystems.
We want to examine the evolving landscape of human-AI ecosystems, focusing on task allocation and role distribution within Human-AI Teams (HATs). Theoretical basis, empirical, and computer simulation-based results are presented. Building on recent empirical findings, it is highlighted that HATs have surpassed human-only teams in complex tasks such as crisis management resource allocation. The chapter explores the general tendencies in task allocations and role assignments and the dynamics of task allocation.
Trust is the main factor affecting task allocation. Trust, among others, depends on explainability in AI agents, suggesting that the ability to articulate reasoning, environmental understanding, and plans enhances trust in AI partners. Studies have shown that while likeability (warmth) influences the selection of team members, AI agents’ perceived competence plays a more significant role in their acceptance and integration into human teams. Shared mental models and effective communication strategies are vital for fostering receptivity and trust in AI teammates. Proactive communication by AI agents has been identified as particularly beneficial for team coordination and situation awareness. Task characteristics also influence their allocations to humans vs. AI agents.
Special attention is paid to the delegation of information processing in HATs. The dynamically adjusted trust provides the basis for dynamic task allocation. Effectively, HAT becomes a self-organizing, optimizing distributed information processing system.
The chapter ends with a discussion of synthesizing research findings to propose strategies for optimizing collaboration within HATs, underscoring the importance of competence, communication, shared understanding, and explainability in the design and implementation of AI agents in team-based settings.
Output: Segram a Python package for narrative analysis
The purpose of the package is to provide tools for automated narrative analysis of text data focused on extracting information on basic building blocks of narratives – agents (both active and passive), actions, events, or relations between agents and actions (e.g. determining subjects and objects of actions), as well as descriptions of actors, actions and events.
The proposed framework is aimed at language understanding and information extraction, as opposed to language generation. Namely, the role of the package is to organize narrative information in convenient data structures allowing effective querying and deriving of various statistical descriptions. Crucially, thanks to its semi-transparent nature, the produced output should be easy to validate for human users. This should facilitate the development of shared representations (corresponding to the WP1 and WP2 motivated goal: “Establishing Common Ground for Collaboration with AI Systems”) of narratives, understandable for both humans and machines, that are at the same time trustworthy (by being easy to validate for humans). This is arguably a desirable feature, for instance, compared to increasingly powerful but hard-to-trust large language models. In particular, the package should be useful for facilitating and informing human-driven analyses of text data.
The package is available at Python Package Index (PyPI) and comes with a full-fledged documentation website at ReadTheDocs platform. The source code is distributed under a permissive MIT license and available at Github.
PyPI. https://pypi.org/project/segram/
Github. https://github.com/sztal/segram
Docs. https://segram.readthedocs.io/en/latest/
2. Medium- and long-term social Impact of Large Language Models and Gen AI.
Large Generative Models (LGMs), like Large Language Models (LLMs), have gained significant influence across diverse domains. However, the growing awareness of potential biases and unfairness in their outcomes raises concerns about the risk of reducing content diversity. This chapter delves into recent research examining the repercussions of recurrent training on AI-generated data, focusing on image generation and LLMs. A specific concern explored is model collapse, a degenerative process affecting generations of learned generative models. This phenomenon results in generated data contaminating the training set for subsequent model generations. Additionally, we explore a proposed simulation framework aimed at investigating the impact of LGMs on critical aspects such as language standardization and diversity.
We developed a comprehensive simulation framework to investigate the dynamics of a self-consuming loop, a process in which a large language model (LLM) undergoes fine-tuning across multiple generations using content it has generated itself. Our framework is built upon LLama, an open-source LLM provided by Meta.
To evaluate the effects of this self-consuming loop, we conducted a series of experiments focusing on the generation of text related to Wikipedia articles. The experiments yielded two significant findings. First, we observed that over successive generations, LLMs subjected to the self-consuming loop exhibit a phenomenon known as “model collapse.” This collapse manifests as a reduction in the diversity of the generated text over time, a result that aligns with recent research findings in the field.
Second, our analysis revealed substantial changes in the linguistic structure of the generated text as the self-consuming loop progresses. Specifically, we noted significant alterations in the frequency of nouns, adjectives, and verbs, alongside shifts in the overall distribution of word frequencies when compared to authentic text. These changes suggest that the loop not only affects content diversity but also distorts the underlying linguistic patterns of the text.
These findings underscore the critical importance of carefully curating and selecting content for fine-tuning LLMs. Neglecting this aspect could lead to undesirable degradation in both the diversity and structural integrity of the generated text, ultimately impacting the model’s performance and reliability.
3 Network effects of human-AI interactions in distributed collaborative learning.
Human-AI interactions are becoming increasingly prevalent in distributed settings characterized by a network of nodes, comprising both humans and AI agents. The ongoing activities in this area are focusing on understanding the implications of these interactions, particularly considering that AI agents can be generative agents (LGMs).
In the realm of decentralized learning, where nodes cooperate to learn a task without the help of a central server, significant progress has been made. Currently, some nodes generate their local data using generative AI (LGMs). This raises critical research questions:
- How robust is a decentralized learning process to accidental or intentional malicious behavior?
- Can the network structure protect the overall training process from such unwanted behavior? For instance, if the most central node learns from corrupted data—such as samples of the digit ‘9’ that look like ‘4’s—how does this affect the learning process? Preliminary findings indicate that decentralized learning is generally robust to single-point malicious data injection, unless the data distribution is pathologically skewed.
Code: https://github.com/ranyus/SaiSim/releases/tag/sabella-v0.1
In the domain of opinion dynamics, models have shown that opinion polarization can be driven by “negative” algorithmic bias. However, ongoing experimental interventional studies provide evidence that “positive” algorithmic bias may backfire. To explore this further, an experiment is underway to study the effects of positive, negative, and absent algorithmic bias (AB) on opinion polarization, as well as the impact of AI units (bots).
- We evaluate the initial opinion distribution through a survey, having participants write texts supporting their views, and exposing them to texts from like-minded individuals (negative AB), opposing individuals (positive AB), or random individuals (absent AB).
- After incentivized interactions, a follow-up survey measures changes in opinion distribution and individual trajectories.
- AI bots with predetermined opinions are introduced to assess their effectiveness in influencing humans and perturbing opinion distribution.
Initial results are promising and indicate nuanced interactions between algorithmic bias and human opinion formation.
Furthermore, the macro-project is actively investigating the generation of content to maximize propagation effects on social networks.
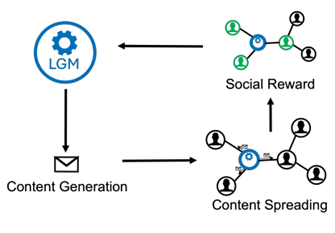
This involves studying user behavior models (e.g., BCM, FJ), large generative models (e.g., Llama, Gemma, Mistral), and discussion topics (e.g., vaccines, Obamacare) to understand their impacts on user behavior and opinion dynamics.
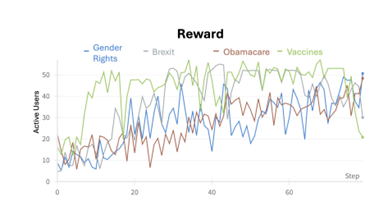
Early findings suggest that content generated to maximize propagation can significantly influence user behavior and opinion distribution, underscoring the power of generative models in shaping online discourse.
Code repository: cannot be shared at the moment due to the anonymity requirement of a submitted paper. It will be shared upon notification

